




What is Sentiment Analysis?
Sentiment analysis is a natural language processing technique to determine the emotional tone behind a series of words, phrases or sentences.
In recent times, sentiment analysis has gained popularity in various fields, such as customer service, brand monitoring, and social media analysis.
With pre-trained language models, such as BERT (Bidirectional Encoder Representations from Transformers), it has become easier to perform sentiment analysis tasks.
This article will explore how to fine-tune a pre-trained BERT model for sentiment analysis using Hugging Face and push it to the Hugging Face model hub.
All the code for this project is available here: GitHub
Why Hugging Face?
Hugging Face is a platform that provides a comprehensive set of tools and resources for natural language processing (NLP) and machine learning tasks.
It offers a user-friendly interface and a wide range of pre-trained models, datasets, and libraries that can be utilized by data analysts, developers, and researchers.
Hugging Face offers a vast collection of pre-trained models trained on large datasets and designed to perform specific NLP tasks such as text classification, sentiment analysis, named entity recognition, and machine translation.
These models provide a starting point for your analysis and save you time and effort in training models from scratch.
For this project, I recommend you take this course to learn all about natural language processing (NLP) using libraries from the Hugging Face ecosystem.
Please, go to the website and sign in to access all the features of the platform.
Read more about Text classification with Hugging Face
Using GPU Runtime on Google Colab
Before we start with the code, it's important to understand why using GPU runtime on Google Colab is beneficial.
GPU stands for Graphical Processing Unit, a powerful hardware designed for handling complex graphics and computations.
The Hugging face models are Deep Learning based, so will need a lot of computational GPU power to train them.
Please use Colab to do it, or another GPU cloud provider, or a local machine having NVIDIA GPU.
In our project, we utilized the GPU runtime on Google Colab to speed up the training process.
To access a GPU on Google Colab, we only need to select the GPU runtime environment when creating a new notebook.
This allows us to fully utilise the GPU's capabilities and complete our training tasks much faster.
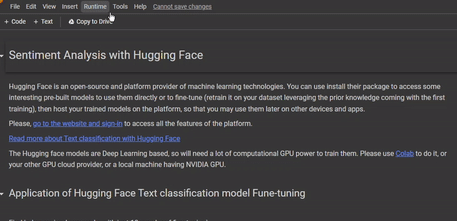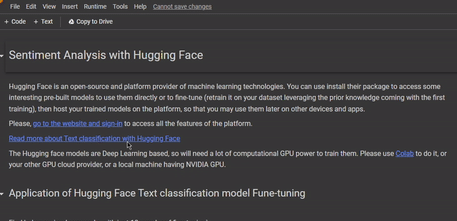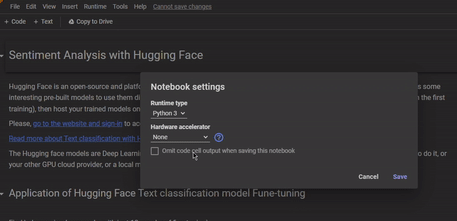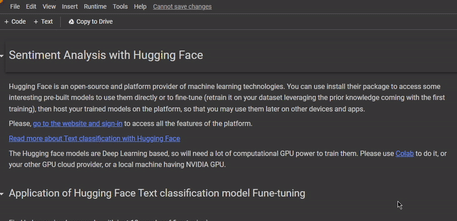
changing runtime to GPU
Setup
Now that we understand the importance of GPU let’s dive into the code. We begin by installing the transformers library, a Python-based library developed by Hugging Face.
This library provides a set of pre-trained models and tools for fine-tuning them. We’ll also install other requirements too.
!pip install transformers
!pip install datasets
!pip install --upgrade accelerate
!pip install sentencepiece
Next, we import the necessary libraries and load the dataset. In this project, we will use the dataset from this Zindi Challenge , which can be downloaded here.
import huggingface_hub # Importing the huggingface_hub library for model sharing and versioning
import numpy as np
import pandas as pd
from datasets import load_dataset
from sklearn.model_selection import train_test_split
from datasets import DatasetDict, Dataset
from transformers import AutoModelForSequenceClassification
from transformers import TFAutoModelForSequenceClassification
from transformers import AutoTokenizer, AutoConfig
from transformers import TrainingArguments, Trainer, DataCollatorWithPadding
# Load the dataset from a GitHub link
url = "https://raw.githubusercontent.com/ikoghoemmanuell/Sentiment-Analysis-with-Finetuned-Models/main/data/Train.csv"
df = pd.read_csv(url)
# A way to eliminate rows containing NaN values
df = df[~df.isna().any(axis=1)]
After loading the dataset and deleting NaN values, we create the training and validation sets by splitting the preprocessed data.
We also created a PyTorch dataset. PyTorch datasets provide a standard format that is more efficient and convenient to use for our machine-learning process.
By following this dataset format, we can ensure consistency in our data handling and seamlessly integrate with other PyTorch functionalities.
# Split the train data => {train, eval}
train, eval = train_test_split(df, test_size=0.2, random_state=42, stratify=df['label'])
# Create a pytorch dataset
# Create a train and eval datasets using the specified columns from the DataFrame
train_dataset = Dataset.from_pandas(train[['tweet_id', 'safe_text', 'label', 'agreement']])
eval_dataset = Dataset.from_pandas(eval[['tweet_id', 'safe_text', 'label', 'agreement']])
# Combine the train and eval datasets into a DatasetDict
dataset = DatasetDict({'train': train_dataset, 'eval': eval_dataset})
# Remove the '__index_level_0__' column from the dataset
dataset = dataset.remove_columns('__index_level_0__')
Preprocessing
Next, we clean the text data and tokenize it. Machine learning models can only understand numbers.
Tokenization is necessary for creating numerical representations of text, commonly known as word embeddings.
Word embeddings are dense vector representations that capture the semantic meaning and relationships between words.
These representations enable machines to understand the contextual information and similarities between words, facilitating more advanced NLP tasks.
For preprocessing, we will use two commonly used functions for text preprocessing and label transformation.

The preprocess function modifies text by replacing usernames and links with placeholders.
The transform_labels function converts labels from a dictionary format to a numerical representation.

Tokenization
checkpoint = "cardiffnlp/twitter-xlm-roberta-base-sentiment"
# define the tokenizer
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
def tokenize_data(example):
return tokenizer(example['safe_text'], padding='max_length')
# Change the tweets to tokens that the models can exploit
dataset = dataset.map(tokenize_data, batched=True)
# Transform labels and remove the useless columns
remove_columns = ['tweet_id', 'label', 'safe_text', 'agreement']
dataset = dataset.map(transform_labels, remove_columns=remove_columns)
We define the checkpoint variable, which holds the name or identifier of the pre-trained model we want to use. In this case, it's the "cardiffnlp/twitter-xlm-roberta-base-sentiment" model.
tokenizer = AutoTokenizer.from_pretrained(checkpoint): We create a tokenizer object using the AutoTokenizer class from the transformers library. The tokenizer is responsible for converting text data into numerical tokens that the model can understand.
def tokenize_data(example): We define a function called tokenize_data that takes an example from the dataset as input. This function uses the tokenizer to tokenize the text in the example, applying padding to ensure all inputs have the same length.
dataset = dataset.map(tokenize_data, batched=True): We apply the tokenize_data function to the entire dataset using the map method. This transforms the text data in the 'safe_text' column into tokenized representations, effectively preparing the data for model consumption. The batched=True parameter indicates that the mapping operation should be applied in batches for efficiency.
remove_columns = ['tweet_id', 'label', 'safe_text', 'agreement']: We create a list called remove_columns that contains the names of the columns we want to remove from the dataset.
dataset = dataset.map(transform_labels, remove_columns=remove_columns): We apply another transformation to the dataset using the map method. This time, we use the transform_labels function to transform the labels in the dataset, mapping them to numerical values. Additionally, we remove the columns specified in the remove_columns list, effectively discarding them from the dataset.
By tokenizing the text data and transforming the labels while removing unnecessary columns, we preprocess the dataset to prepare it for training or evaluation with the sentiment analysis model.
Training
Now that we have our preprocessed data, we can fine-tune the pre-trained model for sentiment analysis. We will first specify our training parameters.
# Configure the trianing parameters like `num_train_epochs`:
# the number of time the model will repeat the training loop over the dataset
training_args = TrainingArguments("test_trainer",
num_train_epochs=10,
load_best_model_at_end=True,
save_strategy='epoch',
evaluation_strategy='epoch',
logging_strategy='epoch',
logging_steps=100,
per_device_train_batch_size=16,
)
We set the hyperparameters for training the model, such as the number of epochs, batch size, and learning rate.
We’ll load a pre-trained model, shuffle the data, and then define the evaluation metric. In this case, we are using rmse.
# Loading a pretrain model while specifying the number of labels in our dataset for fine-tuning
model = AutoModelForSequenceClassification.from_pretrained(checkpoint, num_labels=3)
train_dataset = dataset['train'].shuffle(seed=24)
eval_dataset = dataset['eval'].shuffle(seed=24)
def compute_metrics(eval_pred):
logits, labels = eval_pred
predictions = np.argmax(logits, axis=-1)
return {"rmse": mean_squared_error(labels, predictions, squared=False)}
We can easily train and evaluate our model using the provided training and evaluation datasets by initialising the Trainer object with the parameters below.
The Trainer class handles the training loop, optimization, logging, and evaluation, making it easier for us to focus on model development and analysis.
trainer = Trainer(
model,
training_args,
train_dataset=train_dataset,
eval_dataset=eval_dataset,
tokenizer=tokenizer,
compute_metrics=compute_metrics,
)
Finally, we can train our model using.
trainer.train()
And launch the final evaluation using.
trainer.evaluate()
Find below a simple example, with just 10 epochs of fine-tuning.
Read more about the fine-tuning concept here.
Next Steps
Wondering where to go from here? The next step would be to deploy your model using Streamlit or Gradio, for example.
This would be a web application that your users can interact with in order to make predictions. Here are screenshots of two web apps built with the model we just finetuned.


Conclusion
In conclusion, we have fine-tuned a pre-trained model for sentiment analysis on a dataset using the Hugging Face library. The model achieved a rmse score of 0.7 on the validation set after 10 training epochs.